YÊU CẦU TƯ VẤN SẢN PHẨM
Để được tư vấn nhanh, vui lòng liên hệ Hotline/Zalo: +84 382.933.658






The AIS800-128O is engineered to eliminate bandwidth bottlenecks in next-generation hyperscale AI and ML clusters,. Incorporating the groundbreaking Broadcom Tomahawk® 6 (BCM78910) silicon, it delivers an industry-leading 102.4 Tbps switching capacity with 1024 x 100G PAM4 SerDes technology.
Designed for sub-microsecond latency and high-radix scalability, the AIS800-128O enables the largest flat 2-tier networking topologies, significantly reducing Job Completion Time (JCT) for complex generative AI workloads.
Unmatched PerformanceFeatures the world’s first single-chip 102.4 Tbps silicon (Broadcom Tomahawk 6) with 1024 x 100G PAM4 SerDes, designed for next-gen hyperscale infrastructure. |
High-Density ConnectivityOffers 128 x 800G (OSFP800) ports. Supports up to 512 logical ports (High Radix) on a single chip to maximize network scale. |
AI Workload OptimizationReduces Job Completion Time (JCT) using Cognitive Routing, Dynamic Load Balancing (DLB), and Global Load Balancing (GLB) with sub-microsecond latency. |
Robust System Design4RU form factor with 2+2 redundant 3200W PSUs and 7+1 hot-swappable fans. Includes SyncE and PTPv2 support for precise timing synchronization. |
|
Bandwidth In a Single Device |
Integrated cores. |
Configuration Through Transceiver Type |
|
Sub-microsecond latency |
Delivering the lowest power per bit |
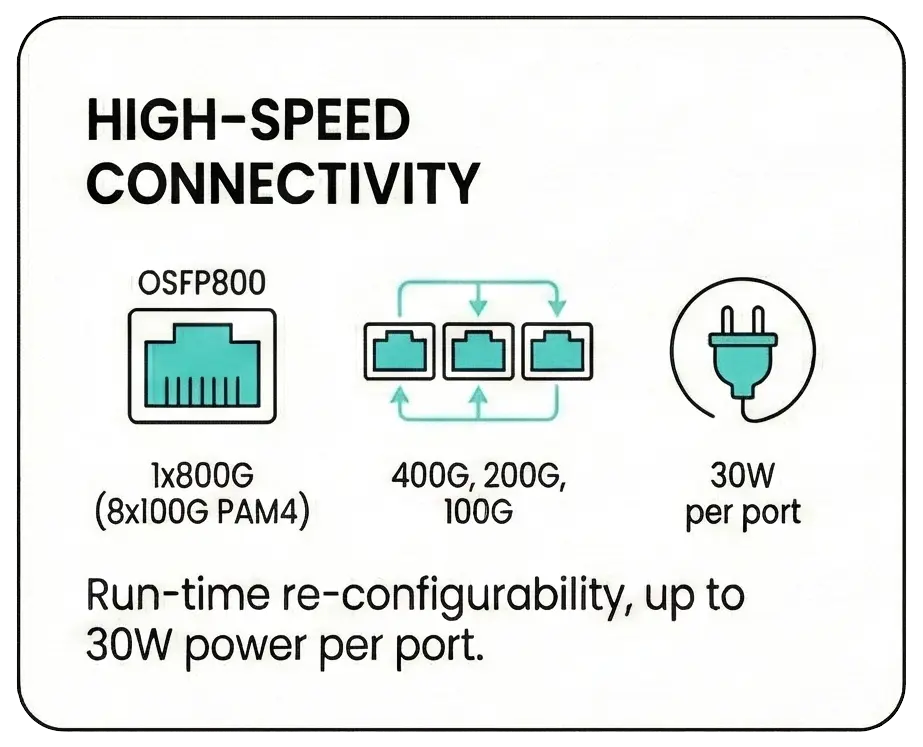 |
High-Speed ConnectivityPort Configuration : OSFP800 switch ports supporting 1 x 800G (8x100G PAM4) or breakout options to 2x400G. Flexport™ Technology : Run-time re-configurability supporting 400G, 200G, and 100G variations. Power : Up to 30W power budget per port for high-performance transceivers (subject to conditions). |
Core Silicon & PerformanceChipset : Broadcom Tomahawk 6P BCM78910 (3nm monolithic process). Scale : Highest Radix with up to 512 logical ports on a single chip. Buffering : 267MB unified, fully-shared packet buffer for burst absorption. Telemetry : Programmable in-band telemetry for real-time network visibility. |
 |
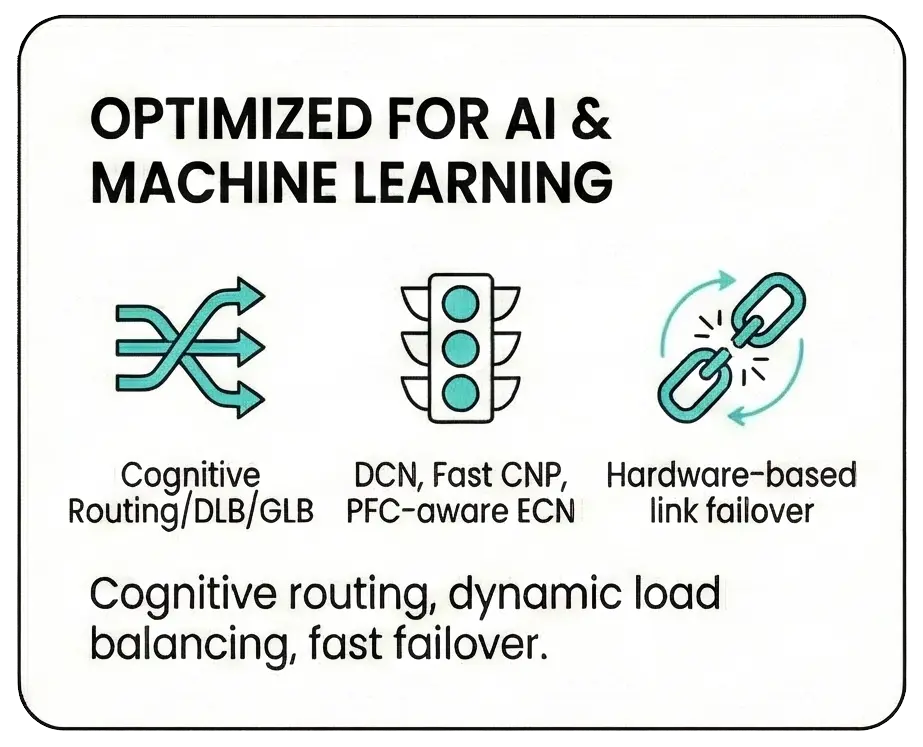 |
Optimized for AI & Machine LearningTraffic Management : Advanced Cognitive Routing, Dynamic Load Balancing (DLB), and Global Load Balancing (GLB). Resiliency : Hardware-based link failover ensures the fastest network recovery and reduces Job Completion Time (JCT). |
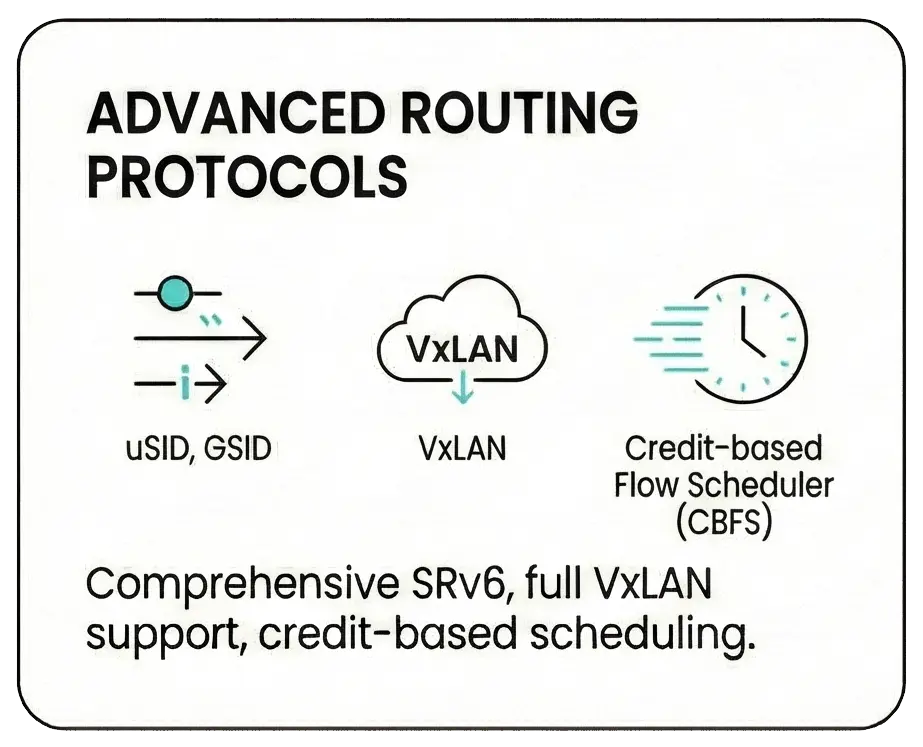
Advanced Routing ProtocolsSRv6 Support : Comprehensive support including Micro SID (uSID), Generalized SID (GSID), and canonical/non-canonical modes (Subject to NOS). Virtualization : Full VxLAN support. Flow Scheduling : Credit-based Flow Scheduler (CBFS) for precise traffic handling (Subject to NOS). |
 |
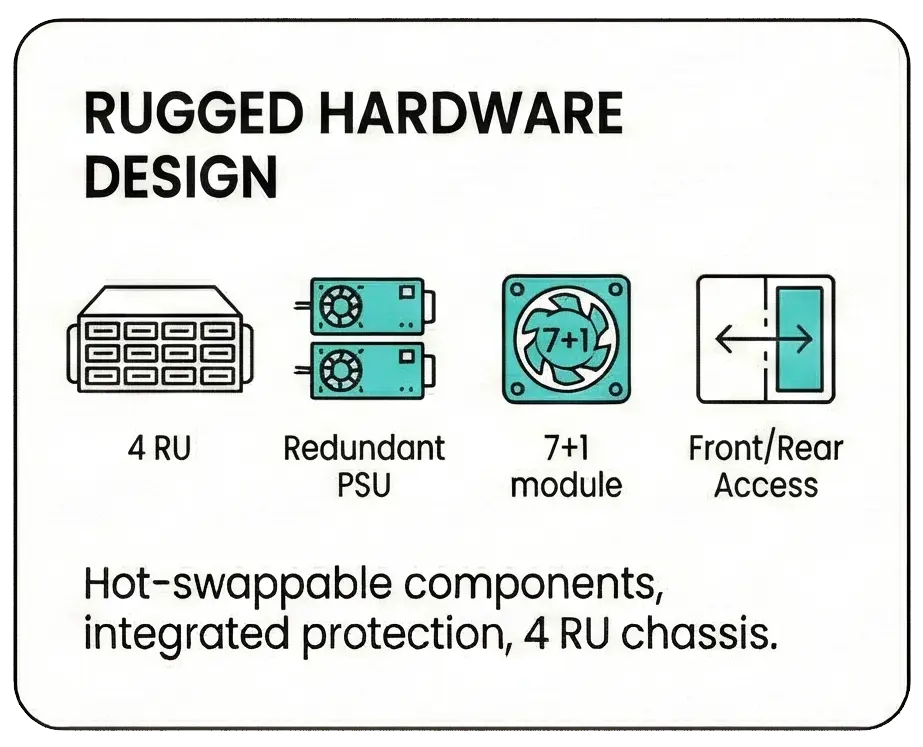 |
Rugged Hardware DesignForm Factor : 4 RU chassis with front-to-back (AFO) airflow. Power & Cooling : Hot-swappable 3200W AC/DC PSUs (redundant) and 7+1 redundant fan modules. Protection : Integrated e-fuses to protect internal components and transceivers. Access : All ports located on the front; PSUs and fans accessible from the rear. |
Management & SynchronizationOpen Networking : Pre-loaded with ONIE for automated installation of community or commercial NOS. Timing : SyncE and PTPv2 support (1PPS, 10MHz, and ToD connectors). Control : BMC module with Serial-over-LAN support. |
 |
|
A next-generation, high-capacity spine switch use case that enables the largest flat 2-tier AI/ML cluster with 400G connectivity. |
Breakout options include 2 x 400G and 8 x 100G with a maximum 512 port radix. Standards-based (Ethernet) networking is ideal for hyperscale AI/ML training that allows the largest flat 2-tier networking with minimum latency, leveraging low latency and high throughput RoCEv2. Breakout options with 2 x 400G enables the largest 400G connectivity in AI/ML clusters. Reduces Job Completion Time (JCT) using the cognitive routing and congestion management capabilities of the switch. Fully programmable telemetry enables sophisticated on-chip applications for heightened network insight and efficient network management. |

Edge-core Networks

Edge-core Networks

Edge-core Networks
Edge-core Networks
Edge-core Networks

Edge-core Networks

Edge-core Networks





Đánh giá
Chưa có đánh giá nào.