YÊU CẦU TƯ VẤN SẢN PHẨM
Để được tư vấn nhanh, vui lòng liên hệ Hotline/Zalo: +84 382.933.658






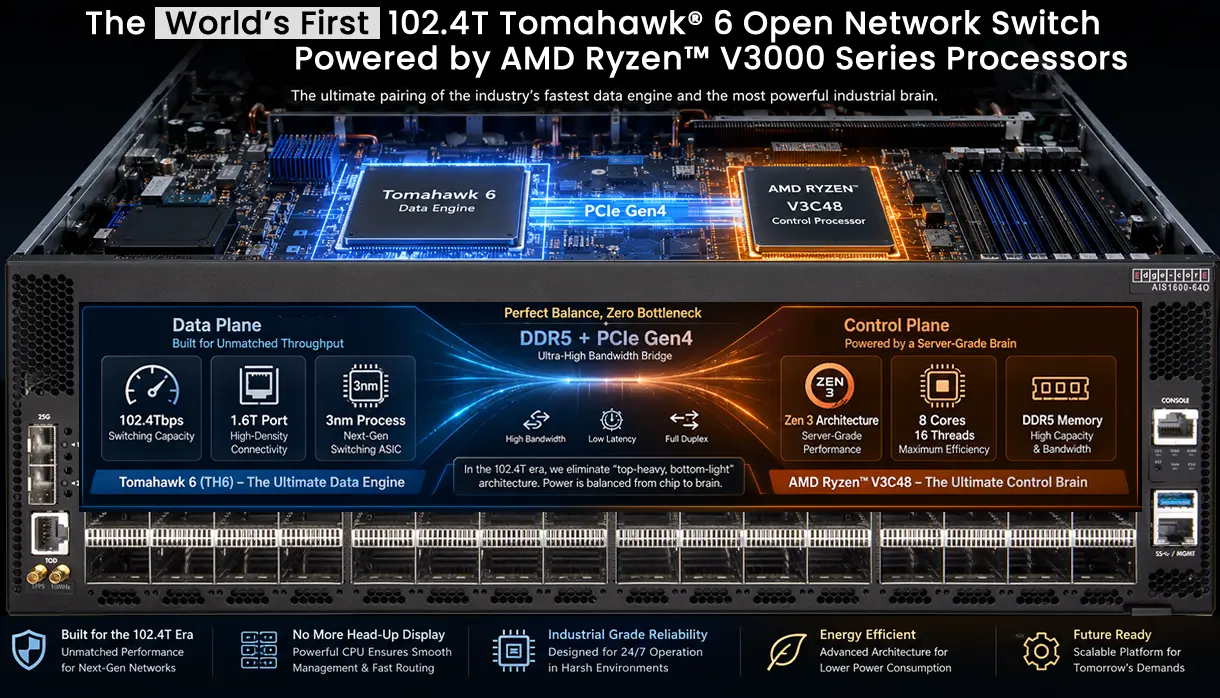
The Edgecore AIS1600-64O is a 64-port 1.6T AI switch powered by Broadcom Tomahawk 6. Delivering 102.4 Tbps capacity and sub-microsecond latency, it eliminates bandwidth bottlenecks for next-gen hyperscale AI/ML clusters.
The AIS1600-64O is engineered to break bandwidth bottlenecks in hyperscale AI and ML clusters. Incorporating the groundbreaking Broadcom Tomahawk® 6 (BCM78914) silicon, it delivers an industry-leading 102.4 Tbps switching capacity with 512 x 200G PAM4 SerDes technology.
Designed for sub-microsecond latency and massive scalability, the AIS1600-64O enables the largest flat 2-tier networking topologies, significantly reducing Job Completion Time (JCT) for complex AI training models.
|
Support for 64 x OSFP1600 ports allows for seamless connection to next-gen 1.6T optics or 800G NICs via breakout options. This high-density 3RU platform eliminates network blocking and maximizes throughput for data-intensive applications
|
Leveraging a monolithic 3nm process die for superior power efficiency. The platform includes programmable in-band telemetry for deep network visibility and includes a powerful AMD Ryzen™ V3C48 CPU for robust management
|
|
Built to handle traffic spikes in AI clusters, the switch features Cognitive/Adaptive routing, Dynamic Load Balancing (DLB), and Global Load Balancing (GLB). Hardware-based link failover ensures maximum resilience and fastest recovery
|
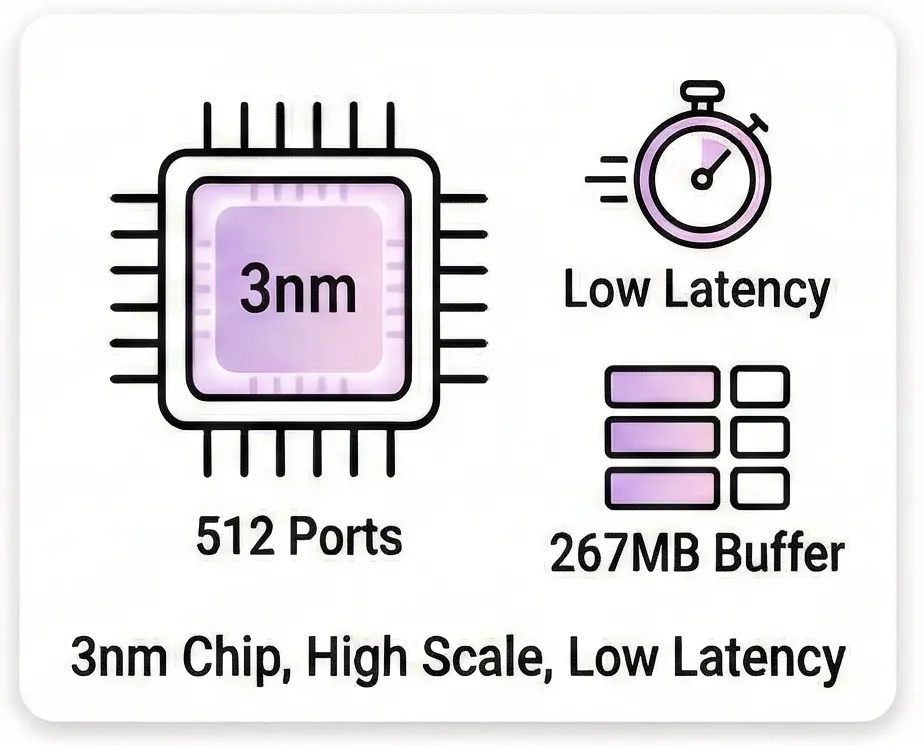
Supporting up to 512 logical ports (Highest Radix) and equipped with a 267MB unified fully-shared packet buffer, the AIS1600-64O effectively manages congestion and micro-bursts without packet loss
|
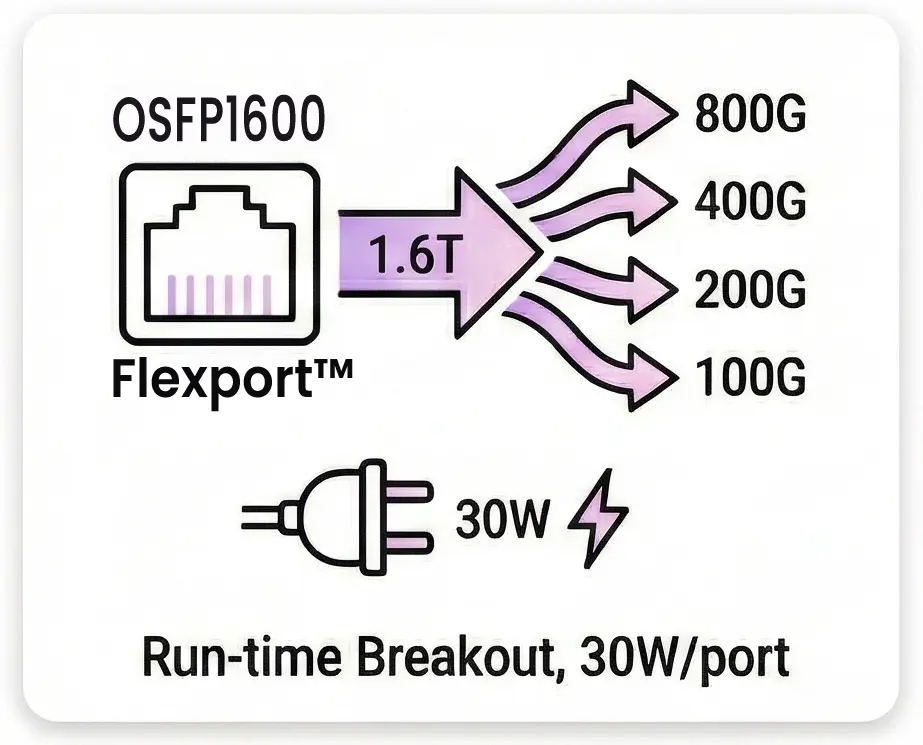 |
Extreme ConnectivityPort Density : 64 x 1.6T OSFP1600 ports. Flexibility : Supports breakout options to 800G, 400G, 200G, and 100G via Flexport™ technology. Power : Up to 30W power budget per port to support advanced transceivers. |
Advanced Silicon & ArchitectureChipset : Broadcom Tomahawk 6C BCM78914 (Monolithic 3nm process). Scale : Highest Radix with up to 512 logical ports per chip. Performance : Low latency design with a 267MB unified, fully-shared packet buffer. |
 |
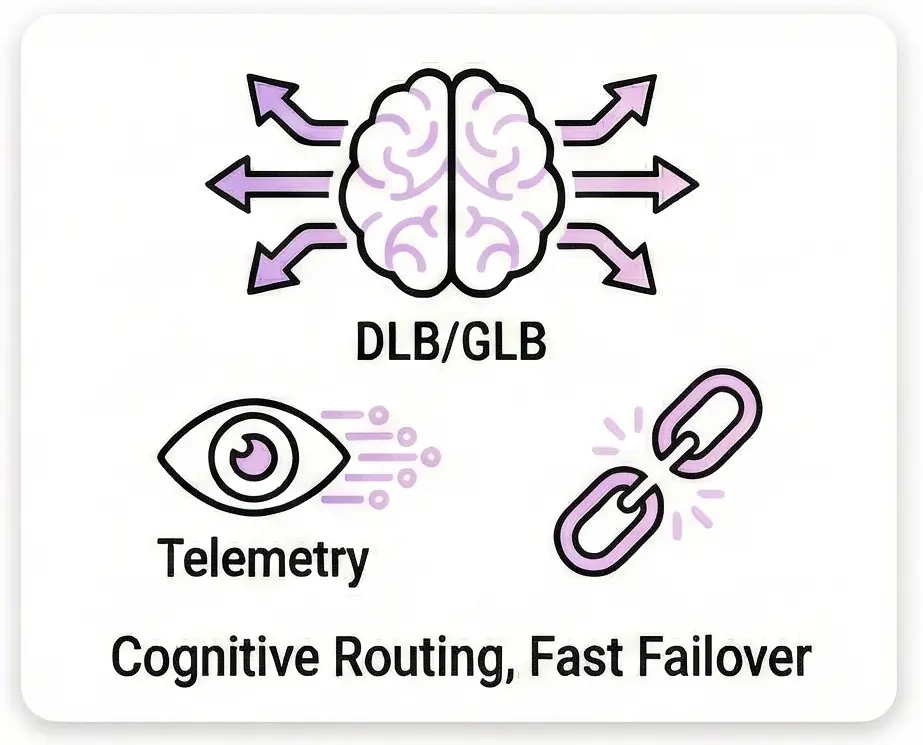 |
Optimized for AI/ML WorkloadsRouting : Cognitive/Adaptive routing with Dynamic (DLB) and Global Load Balancing (GLB). Congestion Control : Features Drop Congestion Notification (DCN), Fast CNP, and PFC-aware ECN. Resiliency : Hardware-based link failover minimizes Job Completion Time (JCT). |
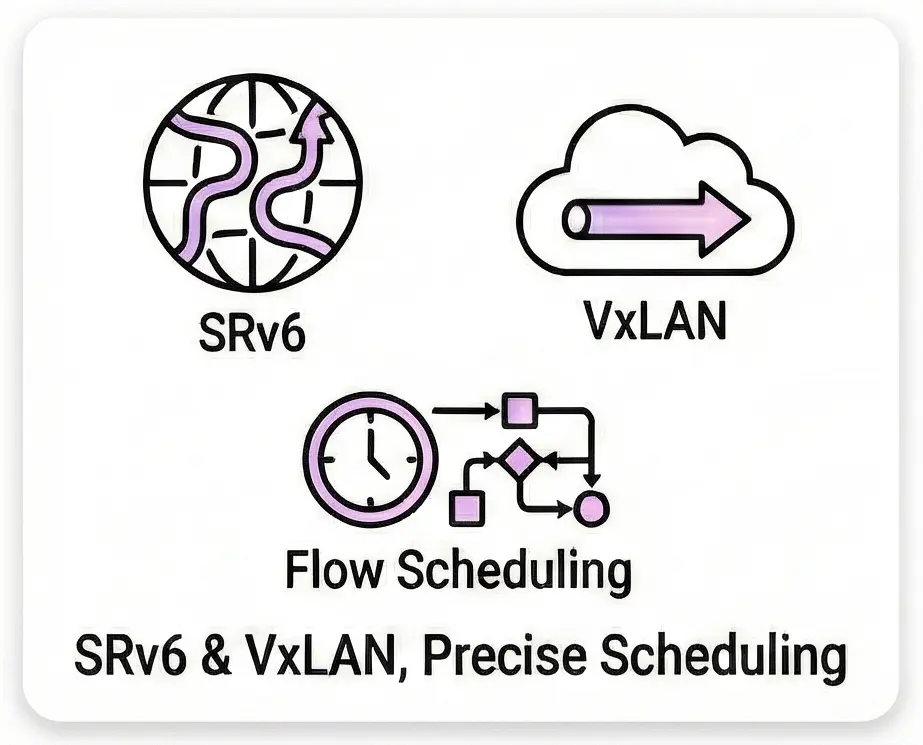
Next-Gen ProtocolsSRv6 : Comprehensive support including Micro SID (uSID), Generalized SID (GSID), and canonical modes (Subject to NOS). Virtualization : Full support for VxLAN. Scheduling : Credit-based Flow Scheduler (CBFS) for precise traffic management (Subject to NOS). |
 |
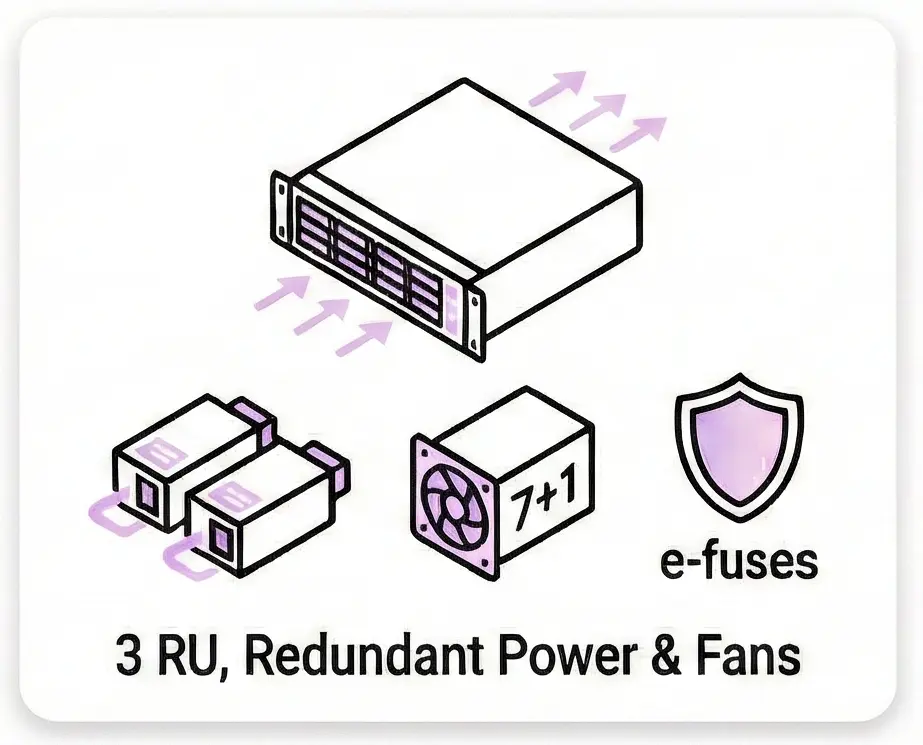 |
Efficient Hardware DesignForm Factor : Compact 3 RU chassis with front-to-back (AFO) airflow. Redundancy : Hot-swappable 7+1 fan modules and load-sharing PSUs (2700W AC or 3200W DC). Safety : Integrated e-fuses for transceiver and component protection. |
Management & SynchronizationOpen Networking : Pre-loaded with ONIE for automated installation of compatible NOS. Precision Timing : Built-in SyncE and PTPv2 support (1PPS, 10MHz, ToD). Control : BMC module with Serial-over-LAN capabilities. |
 |
|
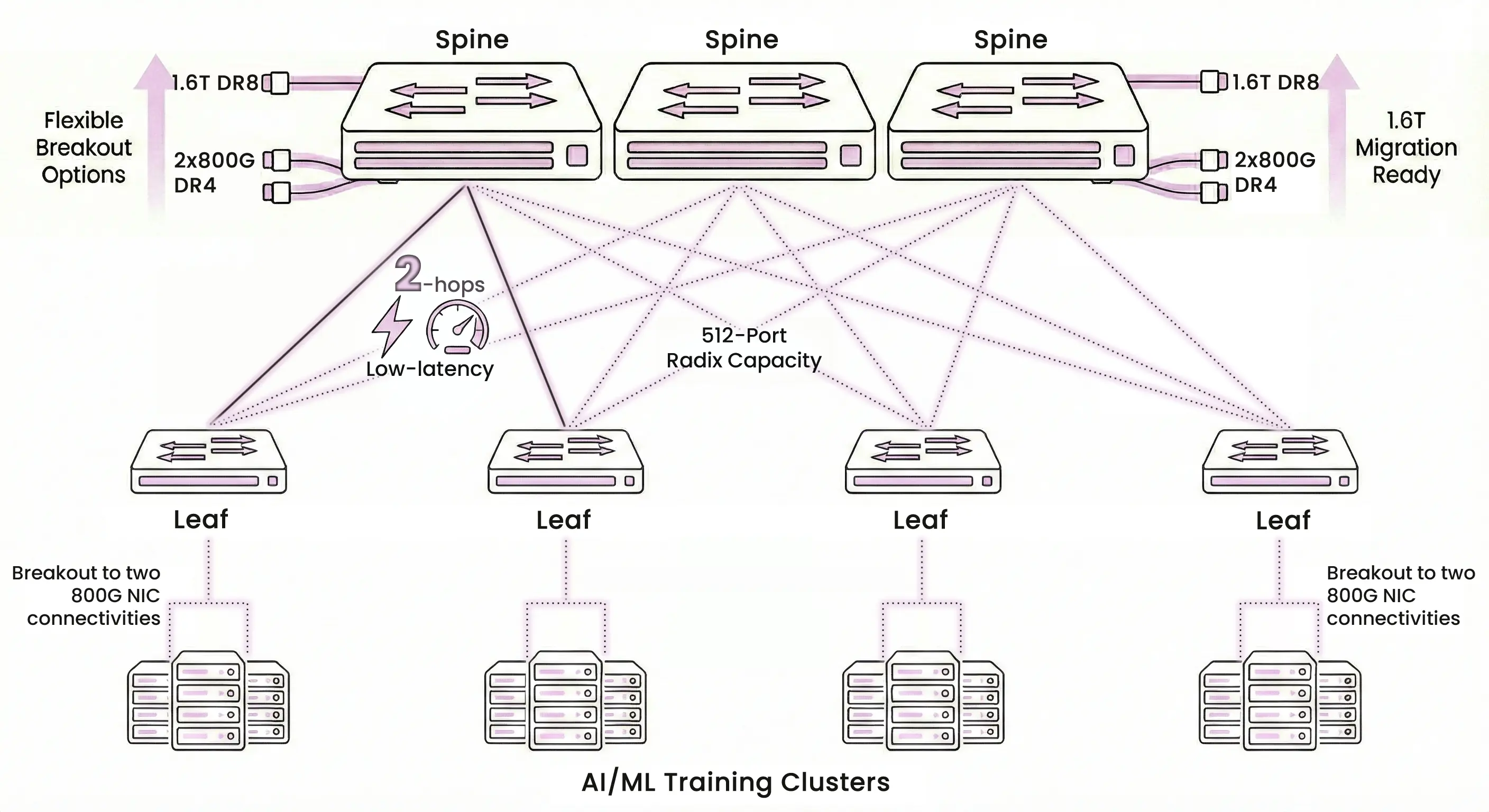
Deploy as a high-capacity spine with 512-port radix support. utilize flexible breakout options (2x800G, 8x200G) to reduce cost and power per bit while enabling seamless migration to 1.6T. |
Ideal for connecting high-throughput 800G NICs in ML training clusters. Supports low-latency RoCEv2 and minimizes network layers for a flat, efficient topology. |

Edge-core Networks

Edge-core Networks

Edge-core Networks
Edge-core Networks
Edge-core Networks

Edge-core Networks

Edge-core Networks



Đánh giá
Chưa có đánh giá nào.